



In the past few months, the testing and evaluation of security solutions have been hot and contentious topics in the cybersecurity industry. There is a continuous debate about the need for industry wide agreement on standards, as well as tools, tactics and procedures (TTP’s) for testing. Considering the importance and ongoing market discussion around this issue, we’ve recently published a white-paper covering best practices and recommendations when it comes to testing and evaluation. In addition, we’ve decided to share our findings and insights on one of the most important components of testing – the malware data sets used and run against security solutions during evaluations. We believe the information provided here will prove to be useful for our customers, testers and industry partners.
Open Malware Repositories
Malware repositories are an important source for threat intelligence providers and consumers, serving security professionals, malware researchers and others. One of their most common use-cases is for building up-to-date data sets to be run against security solutions during testing, evaluations and comparative studies. The results of such tests are a major factor in enterprise rating and decision making concerning the purchase of products and overall IT-security posture.
Therefore, it is evident that the testing process in its entirety, and particularly the detection rate on tested data sets, must be as accurate and representative as possible when a given product’s real capabilities, detection rate and performance are evaluated. Recently, we have encountered more and more security and IT personnel using one or two open repositories as a central, and in some cases, unique source for malware data sets. For this reason, we set out to examine the relevance of relying on these open repositories as a main source for malware testing. We decided to focus our study on a widely used, popular and free repository which we believe can serve as a relevant and interesting test case. This specific repository is often used to test and evaluate security solutions. It gained its popularity due to its ongoing updates, large number of files, and mostly, since it is free, accessible and considered unbiased or geared towards specific solutions or vendors. However, as our analysis shows, relying purely on open and free data sets for creating malware tests, will most likely result in unreliable testing.
Like many other security professionals, we are familiar with and have worked with many of these open repositories for quite some time. We use them mainly as an additional threat intelligence source. However, we quickly became aware of their limitations. The rest of this blog post will examine the reliability, accuracy and content of the repository we chose.
Methodology
We created a data set of 130,000 random samples from the chosen repository for our research purposes (out of millions more available from this specific source. We believe the data set is large enough to represent the entire file corpus and to demonstrate its composition and distribution. We then divided the data set into file types. Partition to file types was used as a basic metric for understanding the relevance of the repository’s collection. We then continued to labeling relevant file types as malware or non-malware samples. This was done based on D-Brain classification, as well as updated scanner data from multiple threat intelligence and file reputation databases we use. We also used the D-Brain malware classification model[1] to further refine the labeling and classification of PE files. All stages of our research included sanity tests – randomly selected files were manually analyzed (both statically and dynamically) to verify and assert the results.
Analysis
Coverage and Sources
The first interesting insight is that 99.96% of the samples in the repository are found in other file threat intelligence services. In most cases, the files collected from open repositories will end up being submitted to such services, either by the repository’s managers or by users. Consequently, most repositories of this kind are not the place to find unique, unseen or rare malware. Rather, they are a resource for hashes and samples found in file-scanning services, and they require minimal registration overhead and are free.
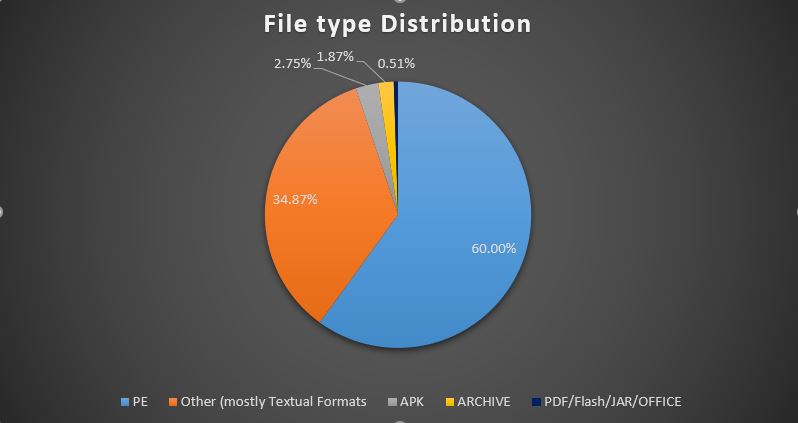
File Type Distribution
Determining the file type[2] of the 130,000 files we’ve collected revealed that only 60% of them are PE files. More than a third of the files, 34.87% to be exact, are made of a mix of different types of text files, and some other file-types that cannot compromise or harm a machine. Another part of the file collection is relevant only for non-Windows environments – APK (Android apps) and small amounts of Linux and MacOS executables were found as well. An additional 0.5% are other formats that can, independently, initiate or partake in an attack vector or infection attempt (i.e. Office, Flash or JAR files), those were analyzed as well.
If so, this repository contains an abundance of files that cannot be used independently as malware and pose no security risk. This means that including them in testing ‘as is’ has no indication of a solution’s ability to prevent or detect malware and any relevant attack vector. Moreover, most solutions which don’t rely on simple hash or binary signatures do not scan or support these files.
[1] This model, which as the rest of the D-brain, is based on deep learning classifies malware to 7 categories: Ransomware, Spyware, Backdoor, Worm, Virus, PUA, Dropper
[2] This was done mainly by processing the output of ‘file’ command on a Linux machine
PE Files
PE files are by far the most common form of malware for Windows machines. Most attack vectors will eventually (if not initially) drop one or more PE files onto the infected machine. That it is why the detection rate of malicious PE’s is a crucial factor in evaluating a security solution and most tests for windows environments focused on PE’s.
As shown before, PE files make up only 60% of this particular file collection and only a fraction more are files with potentially harming behavior. A deeper dive into the PE collection revealed that many of them were not malware at all.
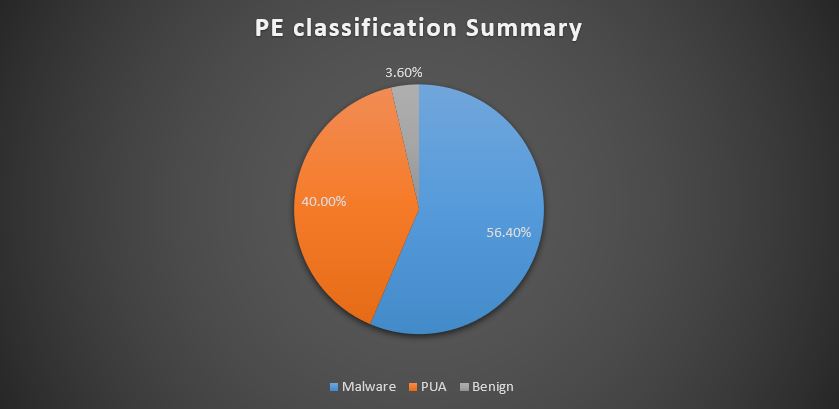
A whopping 40% of the PE files are in fact different types of unwanted applications but definitely not malware. There was very little disagreement on the nature of these files among the different engines we examined and the results correlated well with Deep Instinct’s analysis and classification. These applications are known and were mostly Adware variants, web-search toolbars, system tools, download bundlers, etc. PUA’s are not a good benchmark for comparing security solutions as they are treated differently across different products. Vendors’ and users’ policies regarding PUA varies and in most cases, even when detected, product flow and response methods (if any) would change from product to product and from one IT team to the other.
An interesting piece of data to look at was the overall detection distribution of the PE’s across all scanners we examined. What drew our attention most were these two numbers: First, more than 8% of the files are detected by 10 engines or less, and more than 6% by 6 six engines or less. As these are not newly submitted files, the data indicates the PE collection includes a disturbing number of false positives in an assumed malware only dataset.

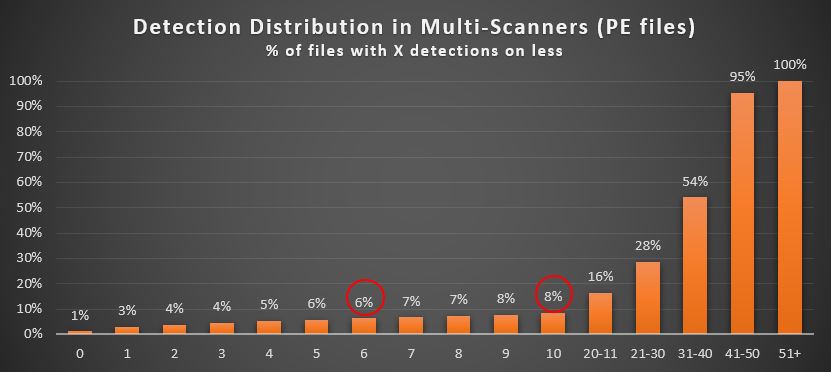
By analyzing files with few detections (5 or less), we were able to confirm with a high level of confidence that 3.6% of the PE’s were benign, legitimate files, many stemming from reputable sources such as Microsoft, Intel, HP Software and Google. Altogether malware files accounted for only 56.4% of all PE files. These numbers indicate the repository includes an aggregate of false positive and non-malware detections from dozens of solutions, resulting in a very noisy dataset.
The next chart summarizes the PE files classification:
Other Format Predictions
Although other potentially malicious file-types account for only a fraction of the collection, we analyzed them as well. The results correlated well with the PE’s distribution. Anywhere between 38% to 64%(!) of the files are not malicious.
Recommendation and Summary
At the bottom line – in a dataset of 130k samples analyzed only 34.28% or 44,564 were found to be relevant malicious samples for testing on Windows machines. The rest of the files are probably found in the file collection because of a false positive or PUA-like detection by some security solutions, or they are not relevant for testing and comparing security solutions.
In today’s competitive security market, evaluating solutions based on tests that provide facts and figures is a must. Testing should be based on relevant, accurate and vetted datasets that are representative of the current threat landscape. Testers should follow guidelines and continuously develop best practices that will ensure their tests results are reliable, and can be used as a reference for comparison.
We’ve demonstrated that creating datasets containing only randomly selected samples from free, open repositories will result in problematic, incomplete and unreliable anti-malware testing. This applies for testing a specific solution, and for conducting comparative evaluations. We strongly believe similar analysis on most other open, free malware repositories will indicate similar numbers and conclusions. These repositories can be a good, accessible source for known malware. However, using them requires pre-filtering and verification (based on threat intelligence and file reputation).
Lastly, keep in mind that even the cleanest dataset originally acquired from an open, shared repository provides the tester only with seen, known malware. Since as a thumb rule, known malware is less challenging, testers should opt for including unknown malware in their tests based on reliable sources and generating their own samples
Contact us for assistance with bundling the evaluation test case on both known and unseen, new malware, using our propriety mutation tool.





