


なぜ最近のEmotetは検知が更に難しくなっているのか

5ヶ月間活動を沈静化していた後、2020年7月17日、よく知られているEmotetが再び進化して登場しました。このボットネットの目的は、被害者から機密情報を盗んだり、TrickBotなどの追加マルウェアのインストールベースを提供したりすることで、その後、多くの場合、ランサムウェアなどのマルウェアを落とすことになります。今回の攻撃では、これまでのところQakBotを配信することが観察されています。
このブログ記事では、我々は最近の新しいEmotetの亜種が活用しているいくつかの新しい回避技術を明らかにします。我々は、その回避技術がどのように動作しているのか、そしてそれらに対応できるのかを発見しました。マルウェア実行の最初の部分はローダーで、この記事では解凍プロセスに重点を置いて検討しています。我々はまた、今回の攻撃の波をいくつかのクラスタに分割しましたが、各クラスタはサンプル間でいくつかのユニークな共有特性を持っています。
サンプルのクラスタリング
Cryptolaemus グループが7月17日から7月28日までに収集したデータを用いて、38,000サンプルのデータセットを作成しました。このグループでは、サンプルを3つのエポックに分けていますが、これは互いに独立して動作する別々のボットネットです。
データセット全体で一貫したパターンを見つけるために、各サンプルから静的解析情報を抽出しました。パターンを特定するために関連する情報には、.text、.data、.rsrcセクションのサイズとエントロピー、ファイル全体のサイズが含まれています。私たちは2つのサンプルから分析を開始しました。それぞれのファイルサイズを見ると、これらのセクションの比率は変わらず、エントロピーはファイル間でほとんど差がないことがわかります。
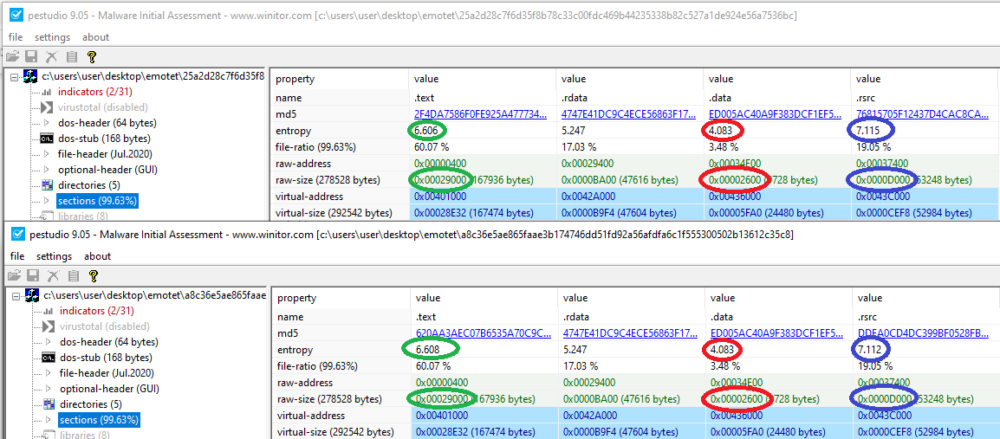
画像は、同じサイズとエントロピーのセクションを持つ、異なるEmotetサンプルを示している
これらは完全に同一のコードです。上記の2つのサンプルをIDA用のdiaphoraプラグインを使用して比較したところ、すべての関数が同一でした。
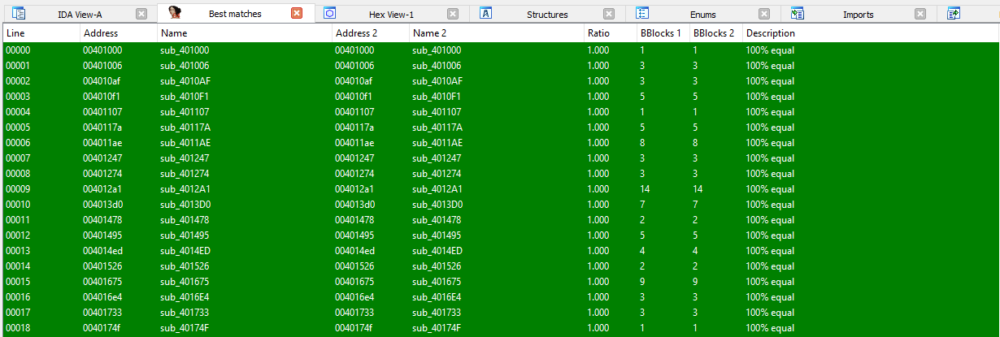
2つのサンプルのコードを比較すると、全く同じサブルーチンを共有していることがわかる
データセット全体をファイルのサイズでグループ化すると、272個のユニークなサイズのファイルが得られました。次に、各サイズにマッチするファイルが、同じ静的情報を持っているかどうかをチェックしました。このようにして、私たちは102個のEmotetサンプルのテンプレートを発見しました。
テンプレートに一致するデータセット内の各サンプルには、Cryptolaemusグループによって示されるように、テンプレートIDとエポック番号がタグ付けされました。これは、各エポックの背後にある演算子が独自のエモテットローダーを持っていることを意味します。様々なテンプレートは、操作全体によって使用されるサンプルの検出率を低下させるのに一役買っているものと思われます。各テンプレートが印付けられた固有の特徴を持っている場合、それによって他のテンプレートやエポックに属するサンプルに影響を与えないことになります。
今日のほとんどのパッカーは、様々な暗号化アルゴリズム、完全性チェック、回避技術などの機能を提供しています。今回確認された複数のテンプレートは、おそらくパッカーソフトウェアのフラグとパラメータの異なる組み合わせの結果です。各エポックはパッキングソフトの設定を変えているだけのため、同じ静的情報を持つファイルのクラスタができあがっています。
良性コードの識別
Emotetローダーには、検知回避を目的として良性のコードが多く含まれています。A.I.ベースのセキュリティ製品は、ファイルを予測分類する際に、悪意のあるコードの特徴と良性コードの特徴の両方に依存しています。そのような製品による検知を回避するために、マルウェアの作者は、検出される可能性を減らすために、実行ファイルに本来不要な良性コードを付加するのです。これは敵対的攻撃と呼ばれ、機械学習に基づくセキュリティソリューションに対して有効です。
Intezer が今回の新種のEmotetサンプルの一部で行った分析を見ると、良性コードは Visual C++ランタイム環境の一部であるMicrosoftのDLLファイルから引用されている可能性があります。別の言い方をすれば、ここで使われている良性コードのソフトウェアはマルウェア検体の機能とは全く関係のないものであるといえます。
以下のスクリーンショットは、diaphoraプラグインを使用して、先ほどのサンプルと良性のMicrosoft DLLファイルとの類似性を示しています:
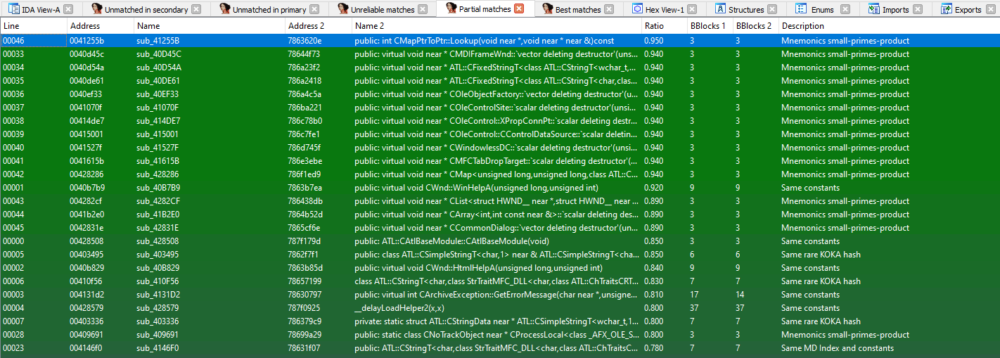
Emotet ローダーには、Microsoft DLL から取られた良性のコードが含まれている
"Name"の列の下にはマルウェアからの関数があり、"Name 2" の列の下には良性のファイルからの関数があります。見てわかるように、マルウェアには必要ではない良性コードが多く含まれています。
次のステップでは、実際にどの程度のコードが使用されているかを確認します。これはDynamoRIOのdrcovというツールを使って行うことができます。このツールはバイナリファイルを実行し、コードのどの部分が使われているかを追跡します。このツールで生成されたログは、後でIDA用のLighthouseプラグインで処理することができます。このプラグインは、実行ログをIDAのデータベースに統合し、どの関数が使用されたかを可視化します。これまでに示したサンプルで解析を行った結果、コードの16.22%しか実際には実行されていないことがわかりました。
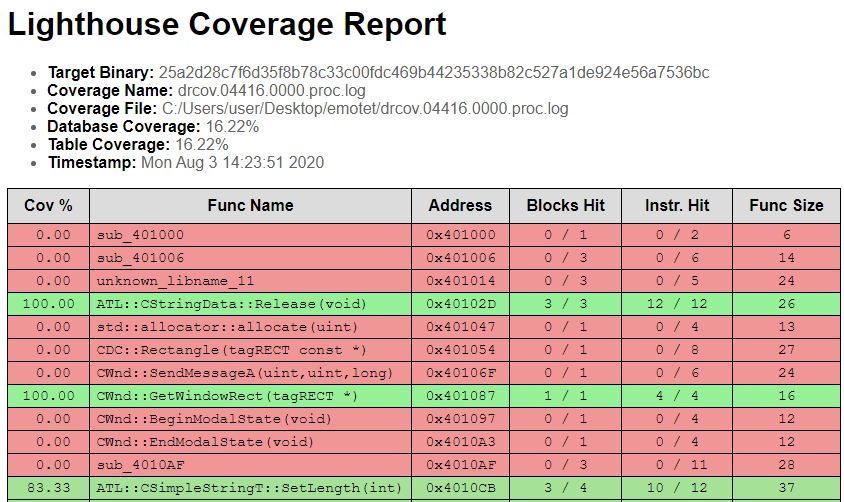
どの関数が実行されたかを示す lighthouse プラグインによって生成されたレポート
私たちは実行可能ファイルに注入された良性コードをフィルタして取り除いた後、すべてのサンプルに存在する悪意のある関数を見つけるために、異なる亜種のコードを比較しました。
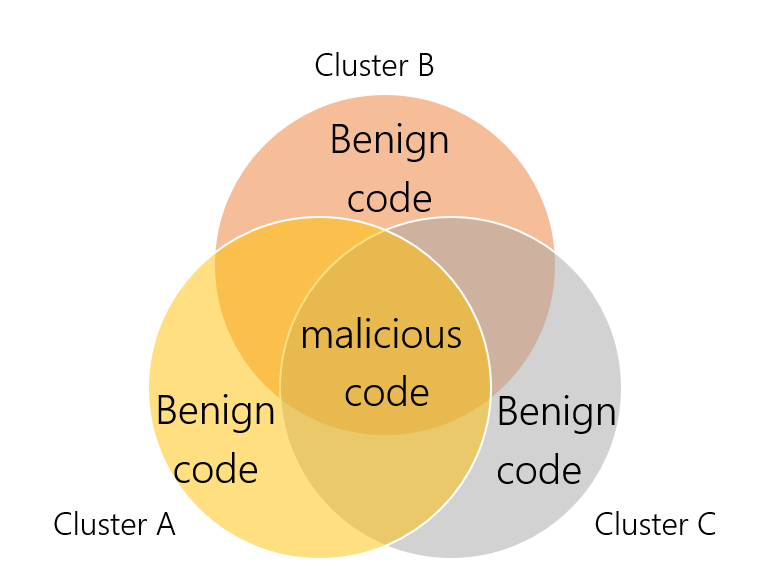
異なるクラスタに含まれる、同じ機能を共有する悪意のあるコードのイメージ
良性コードをフィルタリングすることで悪意のあるコードを明らかにすることができましたが、次のセクションで説明する動的解析を使用して発見することもできます。
暗号化されたペイロードを見つける
先に示した実行ファイルは Emotet ローダです。このローダーの主な目的は、サンプルに隠されたペイロードを解読して実行することです。ペイロードは PE ファイルとそれをロードするシェルコードで構成されています。暗号化されたペイロードによって、存在するセクションのエントロピー値は高くなります。私たちが収集したデータセットによると、87%のファイルがペイロードを .data セクションに、13%のファイルがペイロードを .rsrc セクションに持っていました。pestudioのようなツールは、各セクションと各リソースのエントロピーを表示します。例えば、以下の例ではペイロードを持つサンプルのリソースは、"9248 "という名前のリソースに暗号化されています:

Emotet ローダの中で最もエントロピーの高いリソースを表示する Pestudio
リソースを解読するコードを見つけるために、リソースの先頭にハードウェアブレークポイントを置くことができます。
ペイロードが.dataセクションの中にある場合、どこから始まるかは不明です。セクションの小さな塊のエントロピーを計算することで近似することができ、どこからスコアが上がり始めるかを見つけることができます。
<span style="color: #0000ff;">import</span> sys
<span style="color: #0000ff;">import</span> math
<span style="color: #0000ff;">import</span> pefile
BULK_SIZE = 256
<span style="color: #0000ff;">def</span> <span style="color: #00ccff;">entropy</span>(byteArr):
arrSize = <span style="color: #0000ff;">len</span>(byteArr)
freqList = []
<span style="color: #0000ff;">for</span> b in <span style="color: #0000ff;">range</span>(256):
ctr = 0
<span style="color: #0000ff;"> for</span> byte in byteArr:
<span style="color: #0000ff;">if</span> byte == b:
ctr += 1
freqList.append(<span style="color: #00ccff;">float</span>(ctr) / arrSize)
ent = 0.0
<span style="color: #0000ff;">for</span> freq in freqList:
<span style="color: #0000ff;">if</span> freq > 0:
ent = ent + freq * math.log(freq, 2)
ent = -ent
<span style="color: #0000ff;">return</span> ent
pe_file = pefile.PE(sys.argv[1])
data_section = <span style="color: #0000ff;">next</span>(section <span style="color: #0000ff;">for</span> section in pe_file.sections <span style="color: #0000ff;">if</span> section.Name == b<span style="color: #993300;">'.data\x00\x00\x00'</span>)
data_section_buffer = data_section.get_data()
data_section_va = pe_file.OPTIONAL_HEADER.ImageBase + data_section.VirtualAddress
buffer_size = <span style="color: #0000ff;">len</span>(data_section_buffer)
bulks = [data_section_buffer[i:i+BULK_SIZE] <span style="color: #0000ff;">for</span> i in <span style="color: #0000ff;">range</span>(0, buffer_size, BULK_SIZE)]
<span style="color: #0000ff;">for</span> i, bulk in <span style="color: #0000ff;">enumerate</span>(bulks):
<span style="color: #0000ff;">print</span>(<span style="color: #0000ff;">hex</span>(data_section_va + i*BULK_SIZE), entropy(bulk))
.dataセクションの小さな部分のエントロピーを計算するPythonスクリプト
ペイロードの位置がわかれば、それを解読するコードを見つけることができ、そこから悪意のあるアクションが始まります。
悪意のあるコードを分析する
今回はこちらのサンプルを見てみましょう:
249269aae1e8a9c52f7f6ae93eb0466a5069870b14bf50ac22dc14099c2655db.
このサンプルでは、スクリプトはデータセクションの先頭にペイロードが含まれていることを示していますが、他のサンプルでは異なる可能性があります。ここでは、ブレークポイントをアドレス 0x406100 に設定します。ブレークポイントは、関数 sub_401F80 のアドレス 0x40218C にヒットしています。この関数を見てみると、いくつか怪しい点があります。
1. この関数は、その意図を隠すためにスタック上に文字列を構築しています。この関数は GetProcAddress を使用して VirtualAllocExNuma のアドレスを見つけ、それを呼び出してペイロード用のメモリを確保しています。
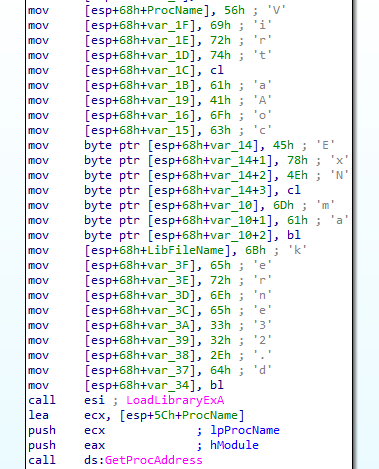
ローダは不審な API 呼び出しを隠している
2. 実行時にVirtualAllocExNumaのパラメータを計算して、RWXメモリの割り当てを隠すようにしています。関数atoiを使って文字列「64」をintに変換していますが、これはPAGE_EXECUTE_READWRITEのことです。また、文字列 "8192 "は0x3000に変換され、MEM_COMMITとMEM_RESERVEフラグでメモリが割り当てられていることを意味します。
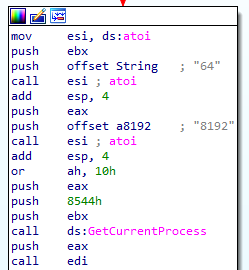
パラメータは、APIコールを難読化するために文字列として保存されていた
ペイロードは.dataセクションからRWXメモリにコピーされます(ここでブレークポイントがヒットします)。そして復号化ルーチンが呼び出され、シェルコードが実行されます。
ローダーはペイロードを解読し、マルウェア実行という次のステップに進みます。
このブログ記事では、新しい Emotet ローダーの静的情報を調べ、類似のサンプルをクラスター化する方法を明らかにし、悪意のあるコードとそのペイロードを見つける方法を見つけました。さらに、ローダーが検出を回避する方法を明らかにしました。主にローダーは、難読化を使用して悪意のあるAPIコールを隠しますが、AIベースのセキュリティ製品の検知アルゴリズムを誤魔化すために良性コードも注入しています。どちらのプロセスも、検体ファイルが検出される可能性を減らすことに寄与しています。これらの積み重ねられた技術の効果により、Emotetグループは脅威の分野で最も先進的なキャンペーンの1つとなっています。
更新
Emotet ローダに隠されたペイロードが解読されて実行され、検出されないようにすることに成功していることについての詳細はこちらの記事をご覧ください。




